1. THE GENETIC
MATERIAL
I. Comparison of Prokaryotes vs Eukaryotes genomes
Organism
genome size
# chromosomes
shape
1. Virus (s stranded)
5 x 103 bp
1
circular
2. E. coli
5 x 106 bp
1
circular
3. Yeast
1.5 x 109 bp
16
linear
4. Human
3 x 109 bp
23
linear
Some thought: the genome in E. coli is 5 x 106
bp = 1.7 x 106 nm = 1.7 x 103mm.
However, the size of E. coli is only about
5 mm!!! How can they pack so much genetic information
in such a small area?
II. Basic structure of DNA
1. Antiparallel
2. Complementarity with regard to bases
3. Chargaff's ratio: always 1 (A=T, C=G).
4. Phosphodiester linkage (ribose to ribose)
5. Base gives: specificity
genetic code
H-bonds (required for double helical structure)
6. H-bonds:
melting/denaturation (G-C content)
Nucleotide components:
1. Sugar: DNA contains the sugar deoxyribose while RNA
contains the sugar ribose
2. Bases: the bases are flat, aromatic and nitrogenous. They
can absorb UV light and are capable
of hydrogen bonding.
Purine bases: (double ring) adenine and guanine
(DNA or RNA)
Pyrimidine bases: (single ring) thymine,
cytosine (DNA or RNA) and uracyl (RNA)
3. Phosphate: up to three phosphate groups are linked as an
ester to the sugar. The phosphates
link nucleotides in the structure of nucleic acids.
They confer a negative charge.
4. N-glycosidic linkage: refers to the type of bond between
the sugar and base
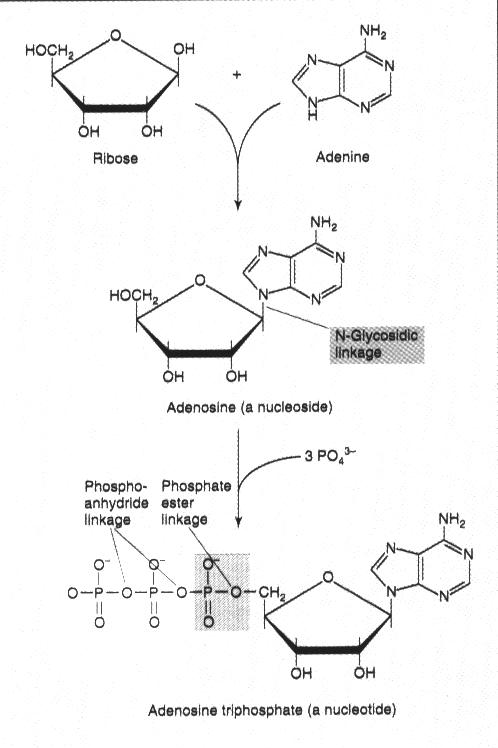
Oligonucleotides
1. Oligonucleotide growth occurs in the 5'to 3' direction
via an attack by 3' hydroxyl groups
upon the
5'
alpha phosphate of nucleotide triphosphates.
2. The resulting linkage is a phosphodiester
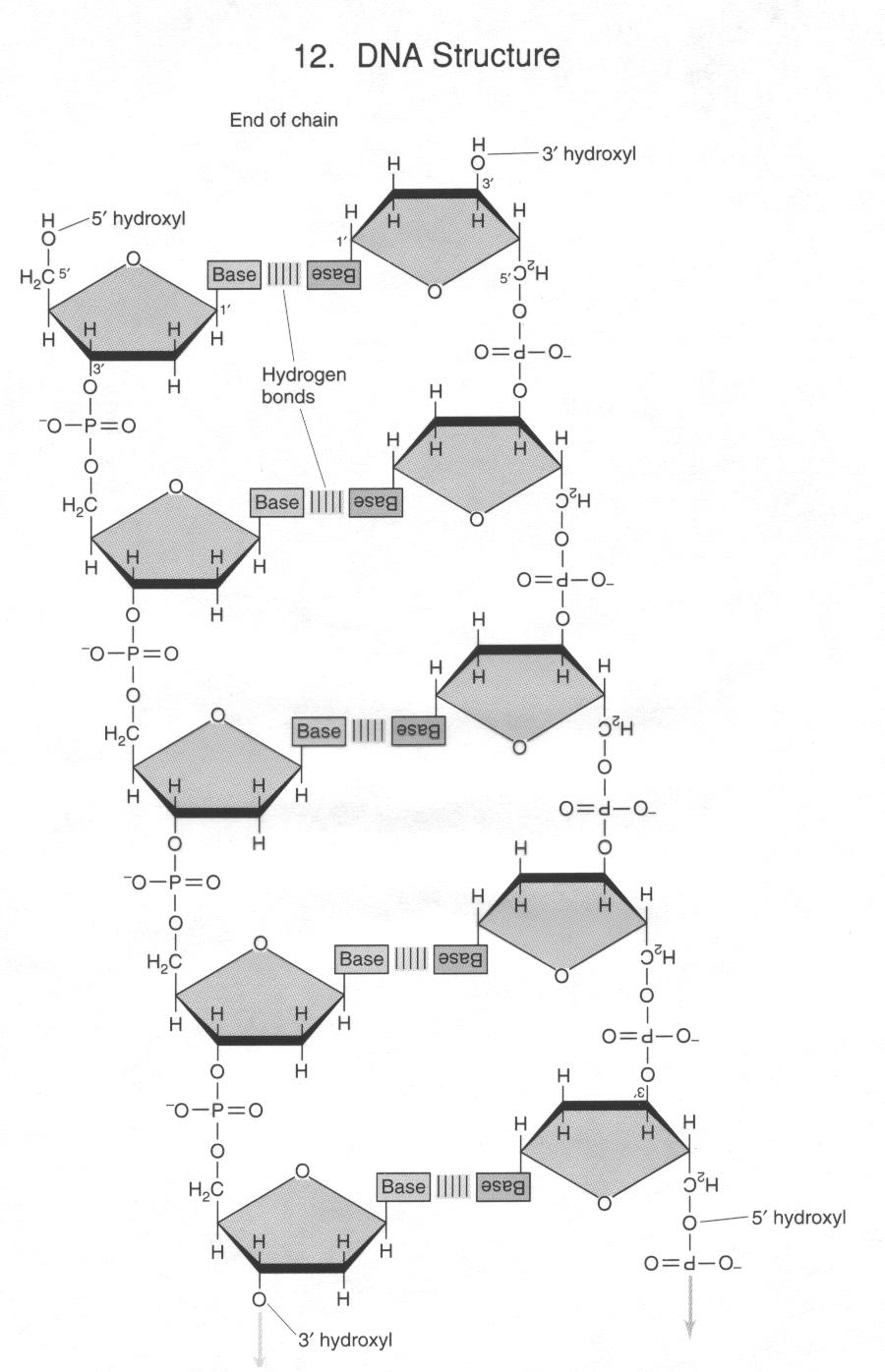
II. NUCLEIC ACIDS (DNA and RNA)
|
DNA
|
RNA
|
1. DNA = deoxyribonucleic acid. The
sugars in DNA
contain a hydrogen
2. DNA is chemically stable
3. DNA contains the bases adenine (A), guanine
(G), cytosine (C), and thymine (T)
4. DNA is double stranded |
1. RN = ribonucleic acid. The sugars
in RNA contain a 2' OH group
2. Due to the presence of the 2' hydroxyl group
RNA is less stable than DNA
3. RNA contains the bases adenine, guanine, cytosine,
and Uracyl (U)
4. RNA is single stranded |
III. GENETIC ELEMENTS (are
structures that contain genetic information)
(This is just extra information and the only thing that you need to
know many kinds of genetic elements are found)
A. Chromosomes carry the information required for life
under all conditions. In bacteria we have a
single chromosome.
B. Non-chromosomal elements are: mitochondria and
chloroplastDNA,plasmids.
1 . Mitochondria and chloroplasts
are organelles believed to have arisen by endosymbiosis.
They
contain DNA, but cannot exist independently.
2. Plasmids are usually circular and
composed of double-stranded DNA. They have their own
orgin ofreplication(ori)
and do not exist extracellularly. They may confer a selective
advantage
(e.g. antibiotic resistance).
DNA Replication:
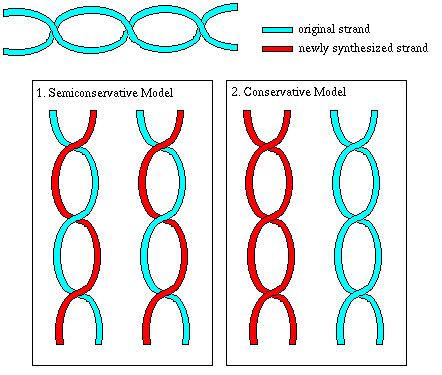
In 1957, Matthew Meselson and Franklin Stahl did an experiment
to determine which of the following models best represented DNA replication:
1. Did the two strands unwind and each act as a template for new strands?
This is
semiconservative replication, because
each new strand is half comprised of molecules from
the old strand.
2. Did the strands not unwind, but somehow generate a new double stranded
DNA copy of
entirely new molecules? This is conservative
replication.
Biochemical Mechanism of DNA Replication
It is very important to know that DNA replication is not a passive
and spontaneous process. Many enzymes are required to unwind the double
helix and to synthesize a new strand of DNA. We will approach the study
of the molecular mechanism of DNA replication from the point of view of
the machinery that is required to accomplish it. The unwound helix, with
each strand being synthesized into a new double helix, is called the replication
fork.
The Enzymes of DNA Replication
1. DNA template
2. Topoisomerase is responsible for initiation of the
unwinding of the DNA. The tension holding
the helix in its coiled and supercoiled structure
can be broken by nicking a single strand of
DNA.
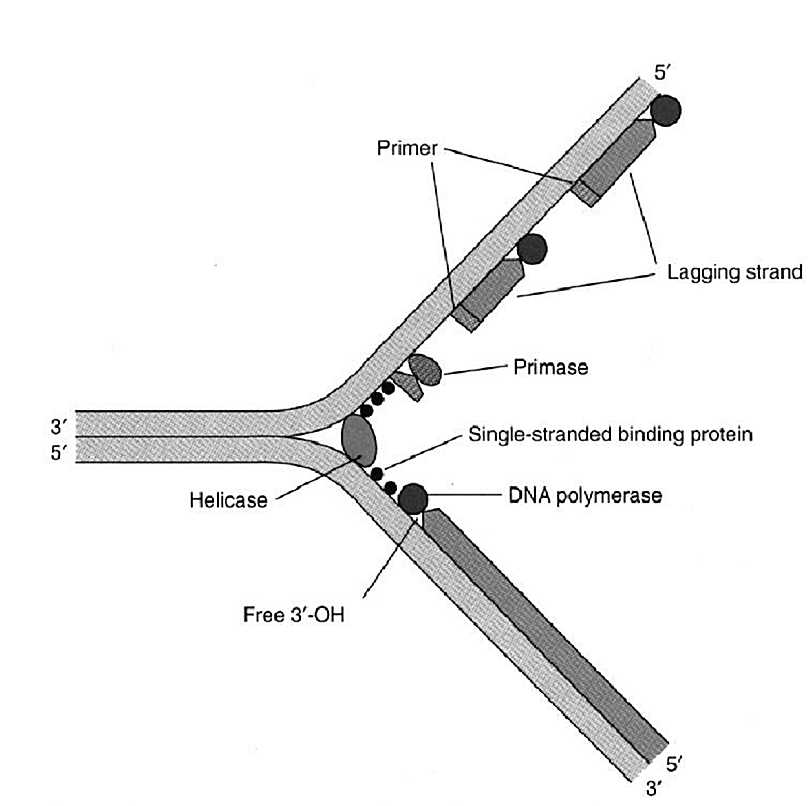
3. Helicase accomplishes unwinding of the original double strand,
once supercoiling has been
eliminated by the topoisomerase.
4. DNA polymerase (III) proceeds along a single-stranded
molecule of DNA, recruiting free
dNTP's (deoxy-nucleotide-triphosphates)
to hydrogen bond with their appropriate
complementary dNTP on the
single strand (A with T and G with C), and to form a covalent
phosphodiester bond
with the previous nucleotide of the same strand.
DNA polymerases cannot start synthesizing
de
novo on a bare single strand. It needs a primer
with a 3'OH group
onto which it can attach a dNTP.
DNA polymerase also has proofreading activities,
so that it can make sure that it inserted the
right base, and nuclease
(excision of nucleotides) activities so that it can cut away any
mistakes it might have made.
5. Primase: This enzyme attaches a small RNA primer to the single-stranded
DNA to act as a
substitute 3'OH for DNA polymerase to begin
synthesizing from. This RNA primer is
eventually removed and the gap is filled in by
DNA
polymerase (I).
6. Ligase can catalyze the formation of a phosphodiester bond
given an unattached but adjacent
3'OH and 5'phosphate. This can fill in the unattached
gap left when the RNA primer is
removed and filled in.
7. Single-stranded binding proteins are important to maintain
the stability of the replication fork.
Single-stranded DNA is very labile, or unstable,
so these proteins bind to it while it remains
single stranded and keep it from being degraded.
The Replication Fork

Why can DNA polymerase only act from 5' to 3'? The reason is
the relative stability of each end of DNA. A triphosphate is required to
provide energy for the bond between a newly attached nucleotide and the
growing DNA strand. However, this triphosphate is very unstable and can
easily break into a monophosphate and an inorganic pyrophosphate, which
floats away into cell. At the 5' end of the DNA, this triphosphate
can easily break, so if a strand has been sitting in the cell for a while,
it would not be able to attach new nucleotides to the 5' end once the phosphate
had broken off. On the other hand, the 3' end only has a hydroxyl group,
so as long as new nucleotide triphosphate are always brought by DNA polymerase,
synthesis of a new strand can continue no matter how long the 3' end has
remained free.
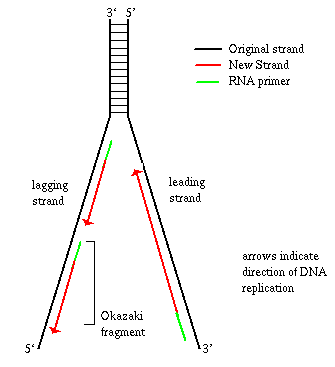
This presents a problem, since one strand of the double helix is 5'
to 3', and the other one is 3' to 5'. How can DNA polymerase synthesize
new copies of the 5' to 3' strand, if it can only travel in one direction?
This strand is called the lagging strand, and DNA polymerase makes
a second copy of this strand in spurts, called Okazaki fragments,
as shown in the diagram. The other strand can proceed with synthesis directly,
from 5' to 3', as the helix unwinds. This is the leading strand.
TRANSCRIPTION:
Transcription involves the construction of an RNA copy
of the genetic information in a DNA template
I. NUCLEIC ACIDS (DNA and RNA)
1. DNA (deoxyribonucleic acid) contains the sugar deoxyribose.
RNA (ribonucleic acid)
contains the
sugar ribose. The difference is DNA contain a hydrogen
RNA contain
a hydroxyl
group in the2'
position.
2. DNA is chemically stable. Due to the presence
of the 2' hydroxyl group, RNA is less stable
than DNA.
3. DNA is double stranded. RNA (except for some
viruses) is single stranded.
4. DNA contains the bases adenine (A), guanine (G), cytosine
(C), and thymine (T). RNA
contains the
bases adenine (A), guanine (G), cytosine (C), and uracyl (U).
II. Basic Prokaryotic and Eukaryotic Processess
Prokaryotes: Polycistronic
- single mRNA contains more than one coding region
Coupled transcription/translation - both functions can occur simultaneously
Eukaryotes: Monocystronic
- single mRNA contains only one coding region
Starts at 5' cap + scans --------> Splicing
(noncoding regions are removed
from RNA before translation
Both: Polysomes -
several
ribosomes translating the same mRNA simultaneously.
Why polycistronic mRNAs and
coupled transcription/translation occur in eukaryotes?
III. Transcription in Prokaryotes and Eukaryotes.
-
Transcription involves the construction of an RNA copy of
the genetic information in a DNA template
-
Eukaryotic transcription is generally more complex than prokaryotic
transcription.
-
mRNA synthesis and processing in eukaryotes
1. Capping - a "cap" is added to the 5' end of
eukaryotic RNA transcripts. A methyl
group is added to the 2' hydroxyl
group of the 5' terminal base of the transcript and
attach a 7-methyl-guanosine
"cap" to the 5' triphosphate end via a 5'--->5' linkage.
3. Addition of a poly-A tail (hundred adenosine)
residues to the 3' end of the transcript.
a. Suppose poly-A is not added - without a poly-A tail, intron splicing
will not
occur, and the mRNA will not be transported out of
the nucleus.
5. Removal of introns - introns are cut out of
mRNA and the remaining exons are spliced
together.
6. Export to the cytoplasm - processed transcripts
travel out of the nucleus and enter the
cytoplasm
where they will be translated.
IV. Gene Structure
A. Prokaryotes vs. Eukaryotes
1. In prokaryotes, genes tend to be clustered in coordinately-regulated
groups called operons.
The genes are transcribed together on a single
transcript and each protein within the cluster is
translated separately. Prokaryotes can "couple"
transcription and translation - i.e. a mRNA
being transcribed can begin being translated even
before transcription is complete.
2. In eukaryotes, genes are not clustered in operons. In addition, eukaryotic
genes often contain
non-coding introns ("intervening sequences")
interspersed among the coding regions (exons).
During RNA processing, introns are
removed from RNA transcripts and the exons are spliced
together. Mature mRNA, after being
transcribed and processed in the nucleus, is transported
into the cytoplasm
where translation occurs. Because transcription and translation occur in
different "compartments"
in eukaryotes, "coupling" of these two processes is not possible.
I
have included my "old notes" for you to use them as supplemental material