 |
Families of Research Designs - Part I
 Just to put things in perspective, cyberspace superstars...
Just to put things in perspective, cyberspace superstars...
We've looked at an overall flowchart or schematic of the entire research design and analysis process.
Next, we spent some time focusing in on research questions or problem statements ... the "heart & soul" of the whole process (It Starts with a Question)
We further focused in by talking about some important components of these research questions/problem statements: namely, variables and hypotheses (Module 3)
Now it's time to move on to the "research design methodology" part of the flowchart. The design methodology (sometimes just called "design") consists of the label(s) that characterize the "general blueprint" of the design. As we'll see, usually more than one design label will apply to a particular study.
As with research questions or problem statements, these design "buzzwords" come in "families." We'll see that many of them "link" to particular "keywords" in our problem statements. Some of them also have to do with the form(s) of data that we are collecting: whether in numbers (quantitative), words (qualitative) or both (multimethod).
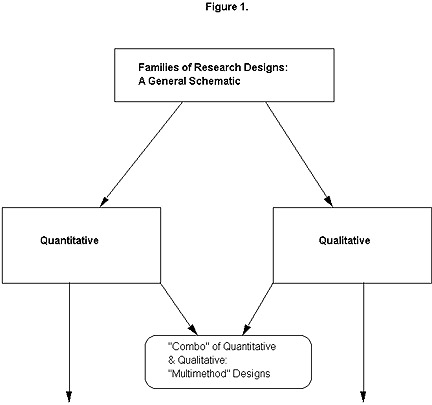
Figure 1 illustrates one basic way to start to break down these design "families:
- Quantitative: data in numbers;
- Qualitative: data in words;
- Multimethod: data in both forms.
Now view a Power Point presentation on quantitative and qualitative
research in more detail.
Qualitative and Quantitative Research Slide Show(Stop slide show at "Time Dimension in Research" slide.)
For example, if you are doing a study where you will be rating students (numerically) on their performance of a sensory-motor skill AND also interviewing these students (data in words) to determine how they perceive their own skill levels (one of the doctoral students whose committee I'm chairing is doing such a study!), then at least one "design methodology label" that would apply is "multimethod."
Now, some design labels apply only to qualitative studies -- while others could apply to a study that's any of the above 3 possibilities. We'll look at the qualitative labels in a future follow-up lesson. For now, let's look at the 2nd possibility: families of design methodology labels that could apply to any/all of the above 3 possibilities.
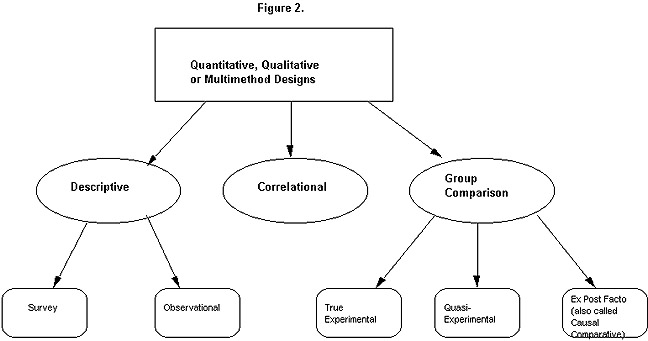
FAMILIES OF DESIGN METHODOLOGY
THAT CORRESPOND TO QUANT/QUAL/MULTIMETHOD STUDIES
Most of these, as we'll see, "link" to certain "keywords" in the research question or problem statement!
I. Descriptive Designs
We've already seen these! And yes -- they link to descriptive questions/statements!
Key characteristics: "what is/what are/identifying/exploratory type studies.
Example: This study is to identify the perceived barriers to successful implementation of the Career Ladder Teacher Incentive & Development Program in X School District.
"Identify"/"what is - what are" (the perceived barriers) - > Descriptive problem statement AND also descriptive research design methodology!
Two "sub-types" (add'l. design methodology labels that could apply to "descriptive designs):"
- Survey - This label also applies to any study in which data or responses (be they quant/qual/both) are recorded via any form of what we think of as "survey instrumentation."
You've probably seen (more than you care to think about! if you've been 'approached' by a 'needy dissertation stage doctoral student' to participate in his/her study!) such surveys. They can take many forms:
- Check-off items (e.g., gender, position);
- Fill-in-the-blank items;
- Likert-type scales (e.g., on a 5-point scale, say, from "strongly disagree" to "strongly agree," you're asked to circle or check your opinion regarding a statement such as, "The Career Ladder Teacher Incentive and Development Program provides ample opportunity for teacher advancement in my district")
- Open-ended fill-in items (you're asked to give a response in your own words, using the back of the survey sheet or extra paper if necessary; something like "Please state the three main reasons you chose to apply for the Career Ladder Teacher Incentive and Development Program this year.")
Types of Survey Research
While often these surveys are paper-&-pencil in
nature (e.g., you're handed one or receive it in the mail & asked to fill it out and return it to the researcher), they are sometimes "administered" orally in a face-to-face or telephone interview (e.g., the researcher records your answers him/herself).
Some Guidelines for Interviews
There are other variations on survey-type questions; the above are just examples of the most common forms and scaling of such responses.
If the responses to our earlier example were collected in the form of a survey
-- be it, say, Likert-scaled attitudinal items and/or open-ended questions
where the teachers are asked to share the perceived barriers in their
own words -- then the study would be characterized as a descriptive
survey design methodology.
- Observational - In these design methodologies, instead of administering a survey instrument, the researcher collects data by observing/tallying/recording the occurrence or incidence of some outcome -- perhaps with the aid of assistants.
He/she might want to identify the most frequently occurring type(s) of disruptive behavior in a particular classroom. With clear prior agreement on what constitutes such "disruptive behavior" (operational definitions of our variables are important, remember?! It becomes an issue of "reliability," or verifiability that "we saw what we saw" vs. "our own bias" of what constitutes this disruptive behavior!), the researcher could develop a listing of such behaviors and observe and record the number of times each one occured in a particular observation session in a classroom. (Again, he/she might wish to 'compare notes' with assistants in order to enhance reliability or verifiability -- e.g., as a cross-check for accuracy).
This type of research would warrant the design methodology label of not only "descriptive" (due to the 'identify/what is - what are [the most frequently occurring ... ]?') but also "observational" due to the recording/tallying protocol.
(By the way, qualitative-type observations can also be recorded. They don't have to be strictly numeric tallies. Examples that come to mind include case notes of counselors, where they record their perceptions in words.)
II. Correlational Designs
We've seen these too! Just as in the case of "descriptive" designs, these "link" to the keywords of "association," "relationship," and/or "predictive ability" that we've come to associate with "correlational" research questions or problem statements!
Correlational Research
III. Group Comparisons
We've briefly talked about "experiments" generally, in terms of "key features" such as the following:
- tight control (the researcher attempts to identify in advance as many possible 'contaminating' and/or confounding variables as possible and to control for them in his/her design -- by, say, building them in and balancing on them -- equal numbers of boys and girls to 'control for gender' -- or 'randomizing them away' by drawing a random sample of subjects and thereby 'getting a good mix' on them -- e.g., all levels of 'socioeconomic status')
- because of the preceding control, the 'confidence' to make 'cause/effect statements'
That is, we begin to get the idea of 2 or more groups, as balanced and equivalent as possible on all but one "thing:" our "treatment" (e.g., type of lesson, type of counseling). We measure them before and after this treatment and if we do find a difference in the group that 'got the treatment,' we hope to attribute that difference to the treatment only (because of this tight control, randomization, and so forth).
Now ... there are actually two "sub-types" of experimental designs. Plainly put, they have to do with how much 'control' or 'power' you as the researcher have to do the above randomization and grouping!
- True experimental - If you can BOTH randomly draw (select) individuals for your study AND then randomly assign these individuals to 2 or more groups (e.g., 'you have the power to make the groups' yourself!), then you have what is known as a true experiment.'
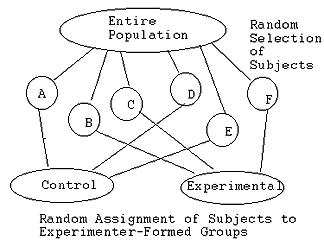
In the preceding scenario, the researcher first:
- Randomly selected subjects A through F from the larger population; AND
- Then randomly assigned these individuals to (experimenter-formed) groups. In our example, by coin-flipping or some other random procedure, Subjects A, D & E "landed" in the control group (e.g., the class that will get the traditional lecture), while Subjects B, C, & F "landed" in the experimental or treatment group (e.g., the researcher-formed class that will get the hands-on science instruction, say).
The two levels of "randomization" help to ensure good control of those pesky contaminating or confounding variables, don't they?! You're more likely to get a "good mix" on all those other factors when you can randomly draw your subjects and also randomly assign them to groups that you as the researcher have the "power" to form!
Ah...but ivory-tower research is one thing; real life quite another ... !
What if you get the OK to do your research within a school district, but the sup't. says, "Oh no! I can't let you be disrupting our bureaucratic organization here and "making your own 4th grade classrooms" for your study! That's way too disruptive! No, no, the best you can do is to randomly select INTACT existing 4th grade classrooms and then go ahead and use all the kids in those randomly drawn GROUPS instead!"
The True Experiment and Quasi-Experiment
Which brings us to the 2nd variant of "experimental designs:"
- Quasi-experimental - what you are 'randomly drawing' (selecting) is NOT INDIVIDUALS but INTACT (pre-existing) GROUPS! These could be existing classrooms, clinics, vocational education centers, etc. In other words, you "lose" the power to "make your own groups" for your study!
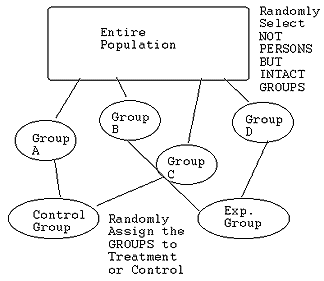
Here (for the quasi-experiment), you randomly draw intact groups (e.g., from all the 4th grades in the district, you draw 4 of them at random) and then flip a coin or use some other random procedure to assign the pre-existing 4th grades to either the "treatment" or "control" conditions. (In our example Grades A and C "land" in the traditional lecture method (control), while Grades B and D end up in the hands-on science instruction (e.g., the "treatment" or the "experimental" group).
Do you see how this is different from the "true" experiment? In the "true" experiment, you selected the children themselves (subjects) at random and then "had the power" to in essence "form" your own "4th grades" by assigning the individual kids themselves randomly to either the control or the experimental conditions.
Here, though, the 'best you can do' (again, often for practical reasons such as access to sites, permission, etc.) is draw not individual kids but the GROUPS themselves (pre-existing 4th grade classrooms) at random and then in step # 2 assigning NOT the INDIVIDUAL KIDS but rather the WHOLE GROUPS to either the treatment or control conditions.
Open the link below for more detailed information about
Quasi-Experimental design
Quasi-Experimental Design
P.S. Do you see how this one-step loss of randomization may mean a bit less control over those pesky contaminants?! By forming your own groups you have a greater likelihood of "getting a good mix on all other stuff". But here, you've got to "live with the existing groups as is." And suppose that in the above scenario, 4th Grades B & D also happen (quite by accident, but welcome to 'real life!') to have a higher average I.Q. of 15 points than A & B! Now we've got a contaminant! Did the kids do better because of the hands-on science lesson -- or because of their inherently higher aptitude, intelligence or whatever?!
But at least we still have that last step: random assignment to either the experimental or control conditions!
Remember ... again ...
- For true experiments, we're randomly assigning individuals to treatment vs. control; and
- For quasi-experiments, we're randomly assigning intact/pre-existing groups to treatment vs. control.
Well -- we lose that "random assignment" property in the 3rd "family" of group comparison design methodologies!
- Ex post facto (also called "causal comparative") - really no 'random anything!' We identify some sort of outcome and wonder 'what makes it vary like that?' Could it be some pre-existing grouping? For instance, if we 'divided' or 'pile-sorted' the responses by gender, would that account for the difference we see?
Thus, there is no treatment either! Simply an attempt to see if a grouping that we had no prior control over seems to "make a difference" on some outcome(s)!
The keyword "difference" (by grouping) and no treatment would be the tip-off to an ex post facto or causal-comparative study design.
And -- regarding the grouping -- maybe this rather silly example will make the point! And help you to identify if you are in such a situation of "no-control-over-grouping:"
You wish to study whether preschoolers from single-parent homes are different in terms of emotional readiness for kindergarten than those of two-parent homes.
Now ... you couldn't go to prospective subjects' homes and say, "OK, now you've got to get divorced ... and YOU have to stay married ... 'cuz that's how you came up in the random assignment!"
I don't think so ... !!! Same thing with "gender:" you took it "as is" (e.g., those subjects in essence 'self-selected into their gender grouping). You had no prior control over 'making' them 'be' one gender or the other but rather took those groups 'as is' and kind of pile-sorted some response(s) by gender to see if it 'made a difference' on some outcome!
Indeed ... the literal Latin translation of "ex post facto" is "after the fact." This shows YOUR role in the 'grouping' process as the researcher! You didn't 'assign' them into any one group, randomly or otherwise. Instead, you came in "after the fact" and wished to see if that self-determined grouping made a difference on some outcome(s) that you are studying!
As you can imagine -- even bigger problems with contaminating variables! There is no randomization or control here!
Thus the name "causal comparative" is sort of a misnomer. You are indeed "comparing" two or more "pre-formed" groups on some outcome(s). But due to that lack of randomization and control, you can't really use this design to study "cause/effect" types of research questions or problem statements. There are generally too many uncontrolled, unrandomized contaminating variables that may have entered the picture to confidently make 'strong' cause/effect statements!
Nonetheless, given the circumstances, this type of design might be "the best you can do." Group differences on some outcome(s) might indeed be interesting to study even though you had little or no "control" in the situation.
To summarize, for the "group comparison" family of designs:
| Kind of Study |
Method of Forming Groups |
Ex Post Facto
(Causal Comparative) |
Groups Formed |
| True Experiment |
Random Assignment of Individual to "Researchr-Made" Groups |
| Quazi-Experiment |
Random Assignment of Intact Groups |
Next time we'll look at some terminology for the "qualitative" branch of design families!

Once you have completed this assignment, you should:
Go on to Assignment1: Identify Design Methodology
or
Go back to Families of Research Designs - Part 1
E-mail M. Dereshiwsky
at statcatmd@aol.com
Call M. Dereshiwsky
at (520) 523-1892

Copyright 1998
Northern Arizona University
ALL RIGHTS RESERVED
|